For a given smooth function 

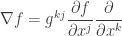
Note that gradient of 
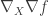
Definition 1. Hessian of
, is defined as the symmetric
-tensor
.
We also denote by 

Thus
![\displaystyle\begin{gathered} {f_{ij}} = g\left( {{\nabla _{\frac{\partial }{{\partial {x^i}}}}}\nabla f,\frac{\partial }{{\partial {x^j}}}} \right) = g\left( {{\nabla _{\frac{\partial }{{\partial {x^i}}}}}\left( {{g^{kl}}\frac{{\partial f}}{{\partial {x^l}}}\frac{\partial }{{\partial {x^k}}}} \right),\frac{\partial }{{\partial {x^j}}}} \right) \hfill \\ \quad\; = g\left( {\frac{\partial }{{\partial {x^i}}}\left( {{g^{kl}}\frac{{\partial f}}{{\partial {x^l}}}} \right)\frac{\partial }{{\partial {x^k}}} + {g^{kl}}\frac{{\partial f}}{{\partial {x^l}}}{\nabla _{\frac{\partial }{{\partial {x^i}}}}}\frac{\partial }{{\partial {x^k}}},\frac{\partial }{{\partial {x^j}}}} \right) \hfill \\ \quad\; = \frac{\partial }{{\partial {x^i}}}\left( {{g^{kl}}\frac{{\partial f}}{{\partial {x^l}}}} \right)g\left( {\frac{\partial }{{\partial {x^k}}},\frac{\partial }{{\partial {x^j}}}} \right) + {g^{kl}}\frac{{\partial f}}{{\partial {x^l}}}g\left( {{\nabla _{\frac{\partial }{{\partial {x^i}}}}}\frac{\partial }{{\partial {x^k}}},\frac{\partial }{{\partial {x^j}}}} \right) \hfill \\\quad\; = \frac{\partial }{{\partial {x^i}}}\left( {{g^{kl}}\frac{{\partial f}}{{\partial {x^l}}}} \right){g_{kj}} + {g^{kl}}\frac{{\partial f}}{{\partial {x^l}}} \left[ \frac{1}{2}\left( {-\frac{{\partial {g_{ki}}}}{{\partial {x^j}}} + \frac{{\partial {g_{ij}}}}{{\partial {x^k}}} + \frac{{\partial {g_{kj}}}}{{\partial {x^i}}}} \right)\right]. \hfill\end{gathered}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%5Cbegin%7Bgathered%7D+%7Bf_%7Bij%7D%7D+%3D+g%5Cleft%28+%7B%7B%5Cnabla+_%7B%5Cfrac%7B%5Cpartial+%7D%7B%7B%5Cpartial+%7Bx%5Ei%7D%7D%7D%7D%7D%5Cnabla+f%2C%5Cfrac%7B%5Cpartial+%7D%7B%7B%5Cpartial+%7Bx%5Ej%7D%7D%7D%7D+%5Cright%29+%3D+g%5Cleft%28+%7B%7B%5Cnabla+_%7B%5Cfrac%7B%5Cpartial+%7D%7B%7B%5Cpartial+%7Bx%5Ei%7D%7D%7D%7D%7D%5Cleft%28+%7B%7Bg%5E%7Bkl%7D%7D%5Cfrac%7B%7B%5Cpartial+f%7D%7D%7B%7B%5Cpartial+%7Bx%5El%7D%7D%7D%5Cfrac%7B%5Cpartial+%7D%7B%7B%5Cpartial+%7Bx%5Ek%7D%7D%7D%7D+%5Cright%29%2C%5Cfrac%7B%5Cpartial+%7D%7B%7B%5Cpartial+%7Bx%5Ej%7D%7D%7D%7D+%5Cright%29+%5Chfill+%5C%5C+%5Cquad%5C%3B+%3D+g%5Cleft%28+%7B%5Cfrac%7B%5Cpartial+%7D%7B%7B%5Cpartial+%7Bx%5Ei%7D%7D%7D%5Cleft%28+%7B%7Bg%5E%7Bkl%7D%7D%5Cfrac%7B%7B%5Cpartial+f%7D%7D%7B%7B%5Cpartial+%7Bx%5El%7D%7D%7D%7D+%5Cright%29%5Cfrac%7B%5Cpartial+%7D%7B%7B%5Cpartial+%7Bx%5Ek%7D%7D%7D+%2B+%7Bg%5E%7Bkl%7D%7D%5Cfrac%7B%7B%5Cpartial+f%7D%7D%7B%7B%5Cpartial+%7Bx%5El%7D%7D%7D%7B%5Cnabla+_%7B%5Cfrac%7B%5Cpartial+%7D%7B%7B%5Cpartial+%7Bx%5Ei%7D%7D%7D%7D%7D%5Cfrac%7B%5Cpartial+%7D%7B%7B%5Cpartial+%7Bx%5Ek%7D%7D%7D%2C%5Cfrac%7B%5Cpartial+%7D%7B%7B%5Cpartial+%7Bx%5Ej%7D%7D%7D%7D+%5Cright%29+%5Chfill+%5C%5C+%5Cquad%5C%3B+%3D+%5Cfrac%7B%5Cpartial+%7D%7B%7B%5Cpartial+%7Bx%5Ei%7D%7D%7D%5Cleft%28+%7B%7Bg%5E%7Bkl%7D%7D%5Cfrac%7B%7B%5Cpartial+f%7D%7D%7B%7B%5Cpartial+%7Bx%5El%7D%7D%7D%7D+%5Cright%29g%5Cleft%28+%7B%5Cfrac%7B%5Cpartial+%7D%7B%7B%5Cpartial+%7Bx%5Ek%7D%7D%7D%2C%5Cfrac%7B%5Cpartial+%7D%7B%7B%5Cpartial+%7Bx%5Ej%7D%7D%7D%7D+%5Cright%29+%2B+%7Bg%5E%7Bkl%7D%7D%5Cfrac%7B%7B%5Cpartial+f%7D%7D%7B%7B%5Cpartial+%7Bx%5El%7D%7D%7Dg%5Cleft%28+%7B%7B%5Cnabla+_%7B%5Cfrac%7B%5Cpartial+%7D%7B%7B%5Cpartial+%7Bx%5Ei%7D%7D%7D%7D%7D%5Cfrac%7B%5Cpartial+%7D%7B%7B%5Cpartial+%7Bx%5Ek%7D%7D%7D%2C%5Cfrac%7B%5Cpartial+%7D%7B%7B%5Cpartial+%7Bx%5Ej%7D%7D%7D%7D+%5Cright%29+%5Chfill+%5C%5C%5Cquad%5C%3B+%3D+%5Cfrac%7B%5Cpartial+%7D%7B%7B%5Cpartial+%7Bx%5Ei%7D%7D%7D%5Cleft%28+%7B%7Bg%5E%7Bkl%7D%7D%5Cfrac%7B%7B%5Cpartial+f%7D%7D%7B%7B%5Cpartial+%7Bx%5El%7D%7D%7D%7D+%5Cright%29%7Bg_%7Bkj%7D%7D+%2B+%7Bg%5E%7Bkl%7D%7D%5Cfrac%7B%7B%5Cpartial+f%7D%7D%7B%7B%5Cpartial+%7Bx%5El%7D%7D%7D+%5Cleft%5B+%5Cfrac%7B1%7D%7B2%7D%5Cleft%28+%7B-%5Cfrac%7B%7B%5Cpartial+%7Bg_%7Bki%7D%7D%7D%7D%7B%7B%5Cpartial+%7Bx%5Ej%7D%7D%7D+%2B+%5Cfrac%7B%7B%5Cpartial+%7Bg_%7Bij%7D%7D%7D%7D%7B%7B%5Cpartial+%7Bx%5Ek%7D%7D%7D+%2B+%5Cfrac%7B%7B%5Cpartial+%7Bg_%7Bkj%7D%7D%7D%7D%7B%7B%5Cpartial+%7Bx%5Ei%7D%7D%7D%7D+%5Cright%29%5Cright%5D.+%5Chfill%5Cend%7Bgathered%7D&bg=ffffff&fg=333333&s=0&c=20201002)
Note that

Since 
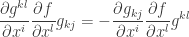
which implies

Definition 2. Laplacian of
, is defined as the trace of
.
Note that

It is clear that 



one has
![\displaystyle\nabla X = \left[ {\frac{{\partial {X^i}}}{{\partial {x^j}}}\frac{\partial }{{\partial {x^i}}} + {X^i}\Gamma _{ji}^l\frac{\partial }{{\partial {x^l}}}} \right] \otimes d{x^j}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%5Cnabla+X+%3D+%5Cleft%5B+%7B%5Cfrac%7B%7B%5Cpartial+%7BX%5Ei%7D%7D%7D%7B%7B%5Cpartial+%7Bx%5Ej%7D%7D%7D%5Cfrac%7B%5Cpartial+%7D%7B%7B%5Cpartial+%7Bx%5Ei%7D%7D%7D+%2B+%7BX%5Ei%7D%5CGamma+_%7Bji%7D%5El%5Cfrac%7B%5Cpartial+%7D%7B%7B%5Cpartial+%7Bx%5El%7D%7D%7D%7D+%5Cright%5D+%5Cotimes+d%7Bx%5Ej%7D&bg=ffffff&fg=333333&s=0&c=20201002)
since 

Definition 3. Divergence of vector field
.
In coordinates, this is

and with respect to an orthornormal basis
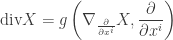
Thus 
NOTICE: To avoid any inconvenience caused, from now we denote gradient of 
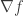

Leave a comment